Czat GPT-4 oraz Bing dostały nową możliwość rozumienia obrazów. To jeszcze nie jest wzrok w pełnym znaczeniu tego słowa, ale jeśli wyślemy do czatów obrazek, to go przetworzą i mogą próbować go opisać, zrozumieć. Bing tę możliwość ma od maja a czat GPT w nowej wersji nazwany GPT-4V stopniowo dostaje tę możliwość. Podobno w Polsce czata 4V będziemy mieli jeszcze tej jesieni.

Zespół badawczy z firmy Microsoft przetestował pod tym kątem sieci neuronowe a wyniki testów stały się pewną sensacją. Znajdziecie je tu: „The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)”, autorstwa Zhengyuan Yang, Linjie Li, Kevin Lin, JianfengWang, Chung-Ching Lin, Zicheng Liu, Lijuan Wang. Wszyscy pracują w Microsoft Corporation. Po polsku tytuł pracy brzmiałby „Świt LLM’ów: wstępne badania możliwości GPT-4V(ision)”
Praca opisuje szereg testów możliwości rozpoznawania obrazów i rozumienia ich znaczeń. I w sumie, nie tylko moim zdaniem, jest to zaskakujące, ile z obrazów rozumie sieć neuronowa. Oto jakie przykłady wynotowałem z tych 166 stron pracy:
Czat GPT-4 dostał zdjęcie człowieka rzucającego frisbee psu i pytanie, w jakiej relacji przestrzennej znajdują się człowiek i talerz. Odpowiedział, że patrząc na zdjęcie, to frisbee znajduje się nad człowiekiem, lekko z przodu i wygląda, jakby oddalało się od człowieka, jakby było przez niego rzucone lub wystrzelone.

Dostał zdjęcie pomieszczenia i polecenie: Załóżmy, że jesteś detektywem. Co potrafisz wywnioskować na podstawie elementów obrazka?

Detektyw-czat odpowiedział tak:
– pokój należy prawdopodobnie do osoby młodej lub nastoletniej, czego dowodem jest swobodne ubranie i biurko z komputerem
– ta osoba przejmuje się ubiorem, czego dowodem jest obecność różnych butów i kurtek
– pokój znajduje się w chłodniejszej strefie klimatycznej, czego dowodem są również kurtki i buty
– osoba mieszkająca w pokoju nie bardzo przestrzega porządku, czego dowodzą zagracone biurko oraz ubrania wiszące na drzwiach
– pokój zapewne znajduje się w starszym lub prowincjonalnym budynku, czego dowodzi widoczna rura oraz zniszczone ściany
Oprócz tego czat pokazał, że w niektórych przypadkach (nie wiemy jak często):
– potrafi zrozumieć wykresy, ilustracje i schematy.
– umie odczytać rachunki i paragony – kwoty oraz suma podatku.
– męczył się z odczytaniem prędkościomierza w samochodzie, ale po podpowiedziach na co patrzeć i jak pracować ostatecznie sobie poradził.
– miał kłopot z liczeniem kilkunastu obiektów na zdjęciu, ale po podpowiedziach i zmianie poleceń policzył poprawnie.
– rozpoznał znane miejsca/turystyczne atrakcje oraz rozpoznał słynne osoby (popularność amerykańska).
Rozpoznał na zdjęciach konkretne dania, np. kuchni amerykańskiej i japońskiej oraz chińskiej – podał składniki dań. Umiał też od razu przetłumaczyć ulotki napisane po chińsku! Tu na przykład, wyjaśnił co przedstawia zdjęcie i skąd jest.

Patrząc na obrazy rozumiał polecenia w różnych językach i umiał też obrazy opisywać w różnych językach (polskiego nie testowali, ale czeski tak).
Rozpoznał stroje ludowe z Etiopii, Indii, Japonii i Chin.
Zinterpretował zdjęcia rentgenowskie czaszki, płuc i kończyn. Jedne poprawnie a inne nie – firma ostrzega, że z powodu możliwych błędnych odpowiedzi czat nie może zastępować lekarskiej diagnozy.
Rozwiązał zadania matematyczne z obrazków i rysunków (a zatem jest szansa, że szkolne zadania też rozwiąże ze zdjęcia).
Wiedział, jak działają strony internetowe, czyli gdzie należy klikać, żeby znaleźć szukanych treści.
Patrząc na sekwencję zdjęć zrozumiał, że mężczyzna nie bije drugiego, ale zadaje mu żartobliwy cios. Tu akurat widać tylko dwa ostatnie zdjęcia z sekwencji.

Bardzo ważne dla rozumienia obrazów jest odpowiednio sformułowane pytanie do czata GPT-4V. W tym sensie nie różni się on innych swoich wersji. Dobre pytanie/polecenie dadzą lepszą reakcję.
Używanie techniki poleceń „paru przykładów” („few-shot prompting”), gdzie najpierw parę razy dajemy podobny obrazek z naszą podpowiedzią, pozwala maszynie nauczyć się reakcji, której oczekujemy.
Skuteczność w odczytywaniu obrazu podwyższa też polecenie powolnego rozumowania „krok po kroku („think step-by-step”). To polecenie każe maszynie, by powoli analizowała obraz, rozpoznając elementy jeden po drugim, coraz więcej dowiadując się o tym, co przedstawia.
Narysowanie strzałek na obrazu lub zakreślenie danych miejsc obrazka poprawiają skupienie uwagi czata na tych elementach obrazu, które chcemy, żeby zinterpretował. Co ciekawe, czat jest wystarczająco mądry i strzałka może wskazywać na obiekt a nie musi go dotykać.
W sieci robi furorę przykład, gdzie czat GPT-4V na podstawie screenshota pokazującego stronę internetową napisał kod kopiujący funkcje tej aplikacji. Czyli sieć neuronowa „spojrzała” na obrazek i na podstawie obrazka napisała kod. Teoretycznie to zadanie byłoby też w zasięgu Binga.
Zobaczcie, jak podobne są te aplikacje!
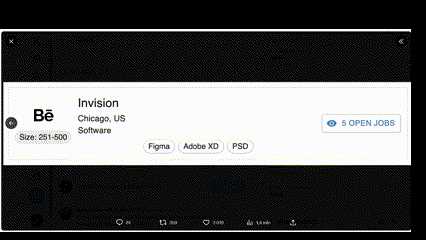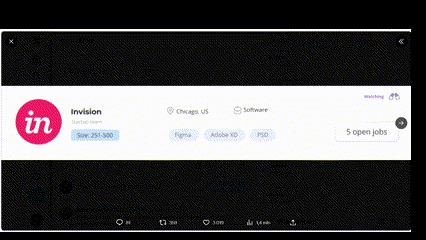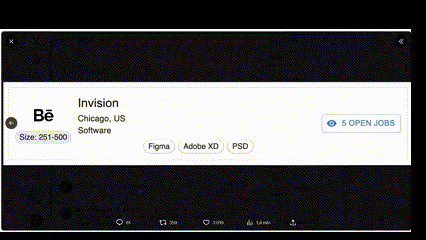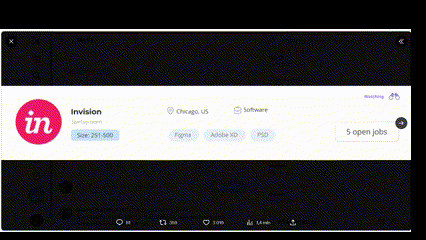
Jeśli czat GPT-4V rzadko będzie się mylił rozpoznając oraz interpretując obrazy, wtedy można używać go w biznesie czy poza biznesem. Można pisać aplikacje, które będą wysyłać do czata automatycznie robione zdjęcia a on będzie je opisywać. Automatyczne rozpoznawanie wypadków samochodowych, bójek to zadania z dziedziny bezpieczeństwa. Automatyczne rozpoznawanie faktur, paragonów oraz działań matematycznych to zadania o charakterze ekonomicznym oraz edukacyjnym. Liczenie obiektów to funkcja przydatna uniwersalnie.
W obecnej chwili mamy do czynienia z interesującą funkcją, ale o nieznanej jeszcze przydatności. Czekamy na testy, na statystyki albo na odważne wdrożenia w biznesie.
Jeśli nie macie dostępu do czata GPT-4 (abonament mies. 20$), to możliwości rozpoznawania polskich obrazów możecie sprawdzić w darmowej wyszukiwarce Bing, która jest częścią przeglądarki Edge (kiedyś to się nazywało Explorer). Binga z wyszukiwaniem obrazowym od czata GPT-4V różni tylko większa cenzura wyników w Bingu (tu link do wypowiedzi szefa tego działu w Microsofcie, który to potwierdził kilka miesięcy temu).
Tę funkcję wysyłania obrazów znajdziemy wyszukiwarce Bing w oknie Zadaj pytanie… Tam po prawej znajduje się ikonka Dodaj obraz. Ona pozwala na wysłanie do sieci neuronowej obrazka, zdjęcia.
Wyjaśnij, przetłumacz, użyj, znajdź – zapewne większość z nas użyje sieci do wyjaśniania obrazów, tłumaczenia czy znajdywania informacji na temat rzeczy na obrazie. Ale może da się zrobić coś bardziej skomplikowanego?
Ja zbieram zdjęcia do moich testów, ale może Wam jakieś ciekawe wyniki wyjdą? Co czat odczyta ze zdjęcia Waszego mieszkania, pokoju, ubrań itd?
