Jeśli media w Twoim kraju najczęściej używają zestawu słów, gdzie najczęściej pojawiają się m.in słowa: „państwo”, „rząd”, „prezydent”, „czas”, „kraj”, „praca”, „wybory” oraz kilkanaście innych, to prawdopodobnie jesteś z kraju, gdzie nie ma silnej demokracji ani silnej gospodarki.
Jeśli zestaw ulubionych słów w mediach w Twoim kraju to m.in: „czas”, „praca”, „dom”, „lubić”, „świat”, „chcieć”, „gra” oraz kilkanaście innych, to najprawdopodobniej jesteś z kraju zamożnego i spokojnego.
To uproszczone wyniki z bardzo ciekawego badania i eksperymentu, który w sumie polegał na tym, żeby sztuczna inteligencja „przeczytała” teksty z anglojęzycznych mediów i zbadała je pod kątem częstotliwości używanych słów. Ten rodzaj sztucznej inteligencji należy do kategorii maszynowego uczenia (Machine Learning) i oznacza inteligentne algorytmy, które testują różne możliwości. Co dokładnie się wydarzyło?

Na platformie PLos One ukazało się badanie „Word differences in news media of lower and higher peace countries revealed by natural language processing and machine learning„. Ten eksperyment naukowy wyglądał tak: wzięto 723 574 artykuły prasowe, zawierające ponad 54 mln słów. Artykuły były po angielsku i pochodziły z 18 krajów, gdzie angielski albo jest językiem urzędowym, albo jest powszechnie używany. Te 18 krajów to były kraje biedne i bogate. To były zarówno kraje, gdzie panuje spokój społeczny a demokracja działa, jak i kraje w większym stopniu targane konfliktami społecznymi i politycznymi: Australia, Bangladesz, Filipiny, Ghana, Hong Kong, Indie, Irlandia, Jamajka, Kanada, Kenia, Malezja, Nowa Zelandia, Nigeria, Singapur, Sri Lanka, Tanzania, Wielka Brytania, USA.
Naukowcy i naukowczynie wyliczyli dla każdego z tych krajów ocenę, która była średnią z pięciu, światowych rankingów pokoju, rozwoju i dobrobytu: Global Peace Index (GPI), Positive Peace Index (PPI), Human Development Index (HDI), World Happines Index (HPI), Fragile State Index (FSI).
Jednocześnie teksty z każdego kraju zostały przez sztuczną inteligencję ocenione na podstawie częstotliwości słów i otrzymały ocenę, która miała pokazywać, czy to są słowa z kraju o wysokim poziomie pokoju, czy niższym (ML Peace Index). W tym wypadku nie mówimy o sztucznej inteligencji, jako o sieci neuronowej. Sztuczną inteligencją w tym przypadku były algorytmy. Te konkretne algorytmy mają nawet swoją ładną i ciekawą nazwę: Losowy Las (Random Forest). Możemy się domyślać, że zostały uruchomione na komputerach jakiegoś centrum obliczeniowego
Czy te dwie oceny, ludzka i komputerowa ocena w jakikolwiek sposób są zbieżne? Czy analizując częstotliwość słów używanych przez media danego kraju, można przewidzieć, czy kraj jest wysoko lub nisko w hierarchii krajów mierzonych pod kątem pokoju, rozwoju, szczęścia, dobrobytu oraz niepokojów? Zdecydowanie tak.
Współczynnik korelacji wyniósł r2 = 0.8349, czyli obydwa wskaźniki, ten maszynowo-językowy oraz ten rankingowy pokrywają się w ponad 80%.
Klasyczna i pomysłowa zarazem była metoda obliczania tej zależności. Porównajmy słowa z tych tekstów do nasion. Losowo wybierane zestawy słów zostały w pewnym sensie zasiane, bo na ich podstawie algorytm Lasu Losowego (prawdziwa nazwa!) obliczał, jak często pojawiają się w tekstach z krajów bogatych i spokojnych czy krajów mniej zamożnych i mniej spokojnych. Powstawało drzewko możliwości, gdzie kolejne słowa zostawały lub odpadały, jeśli okazywało się, że obecność słowa w zestawie nie pomaga w przewidzeniu poziomu dobrobytu i spokoju kraju.
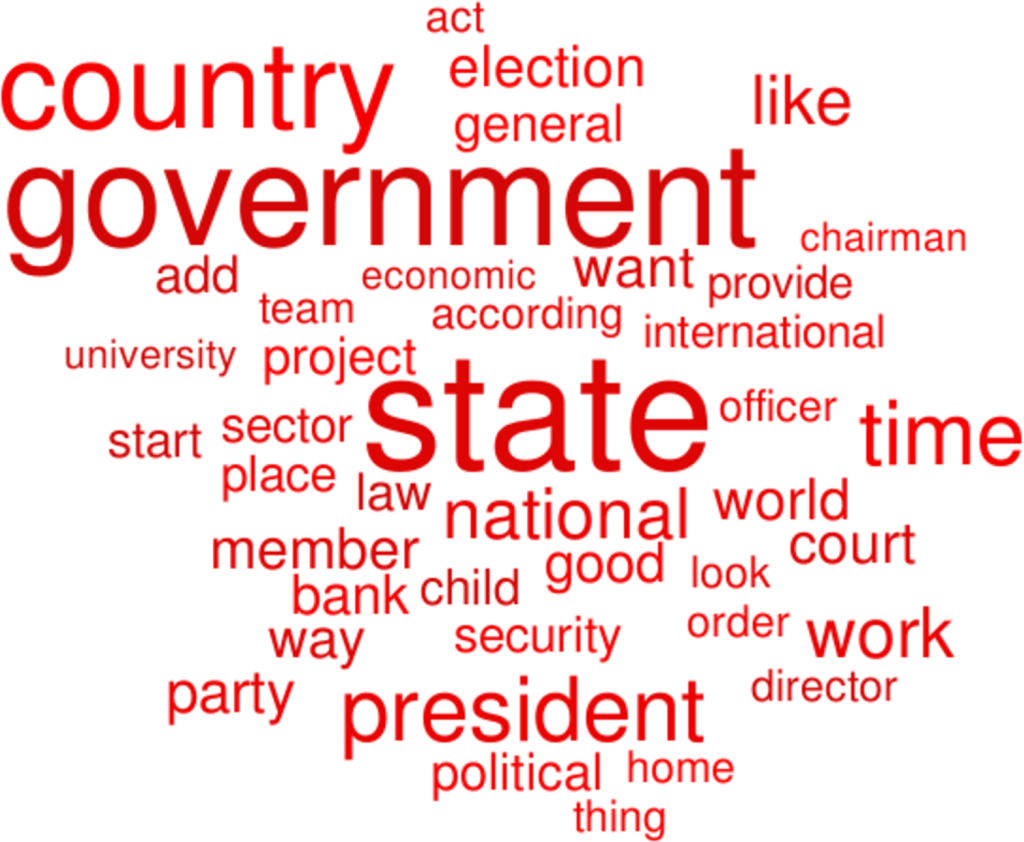
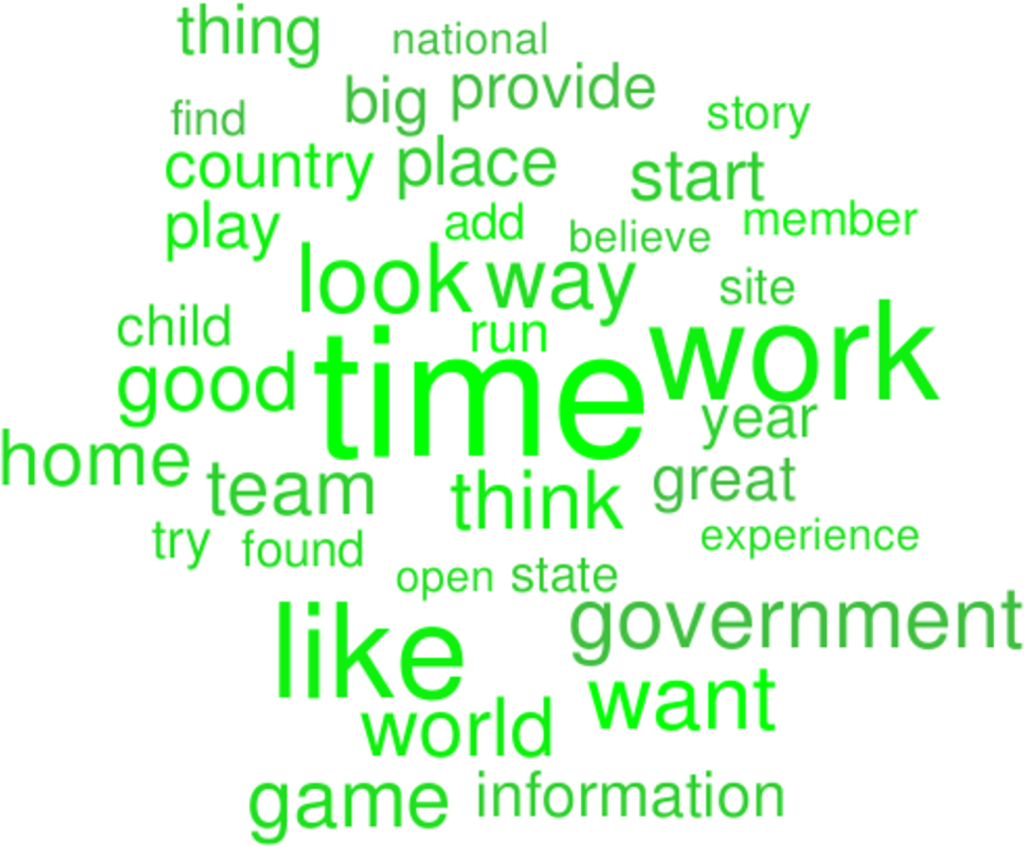
W ten sposób powstał taki las wyników i na jego podstawie mogły powstać te chmury słów. Im większe słowa w chmurze, tym częściej dane słowo było kluczowe dla algorytmu w odróżnianiu krajów o różnym poziomie spokoju i dobrobytu.
Jakie to badanie może mieć konsekwencje i jakie ma słabe strony?
Słabe strony są oczywiste: dotyczyło tylko języka angielskiego. Nie wiemy, czy dotyczy też innych języków. Źródłem słów są artykuły prasowe i teksty medialne. Być może jeszcze skuteczniej można przewidywać dobrobyt i pokój w danym kraju na podstawie słów używanych przez ludzi niepracujących w mediach, ale pracujących gdzie indziej? Może cała populacja? Może tylko niektórzy?
Maszynowa analiza językowa potencjalnie byłaby bardzo przydatna w badaniach polityki czy społeczeństwa. Stałaby się cennym uzupełnieniem np. sondażowych badań opinii publicznej.
Czy ten rodzaj analizy da się zastosować wobec języka konkretnych grup społecznych, konkretnych ludzi i w ten sposób maszynowo wychwytywać zależności miedzy częstotliwością używania słów a na przykład stanem zdrowia? Zapewne tak! Również w Polsce zespół badawczy „Psychiatria i fenomenologia obliczeniowa” z IDEAS NCBiR chce uruchomić eksperyment, w ramach którego analiza tekstów mogłaby pomóc w diagnozie autyzmu czy schizofrenii. Teksty pisane przez konkretnych ludzi, mogłyby np. na podstawie częstotliwości słów zwiększyć trafność diagnozy problemów psychicznych.
Nie tylko częstotliwość słów może być istotna w analizie językoznawczej. Wymowa słów, akcentowanie, głośność wypowiedzi – również te cechy mowy mogłyby być maszynowo analizowane. Teoretycznie już teraz w zasięgu technologicznym byłoby badanie, gdzie na podstawie cech wypowiedzi a tym bardziej tekstu maszynowo ustalane byłoby prawdopodobieństwo np.: stanu emocjonalnego, pochodzenia społecznego czy etnicznego, stanu zdrowia.
Zespół naukowy, który przeprowadził to badanie nie rozstrzyga, czy to słowa decydują o bogactwie i spokoju danego kraju, czy słowa tylko odzwierciedlają bogactwo i spokój. W jakim stopniu nasz język tworzy nasze bogactwo albo nasze niepokoje?
