TL;DR – Eksperyment pokazał, że odpowiedzi dużego modelu językowego (LLM) mogą pokrywać się z odpowiedziami ludzi w badaniach rynkowych percepcji marek – w tym badaniu marki samochodów (brand perceptual analysis). Czat GPT4 w promptach otrzymywał m.in prompty typu „Act as”: Zachowuj się, jakbyś posiadał samochód marki X. Na ile prawdopodobne jest, by twoim kolejnym samochodem był samochód marki Y. Udziel odpowiedzi używając liczb, na skali od 0 (bardzo mało prawdopodobne) do 10 (bardzo prawdpodobne).” Udzielane odpowiedzi czata pokrywały się w znaczny sposób (powyżej 75%) z odpowiedziami ludzi oraz realnymi wyborami osób kupujących samochody. Inny eksperyment pokazał, że odpowiedzi czata GPT-3,5 generalnie były zgodne z modelami ekonomii a deklaracje chęci kupna produktów czy usług pokrywają się z wynikami badania preferencji ludzi.

W badaniu „Determining the Validity of Large Language Models for Automated Perception Analysis” chodziło o sprawdzenie, czy czat GPT4 będzie przydatny w zbadaniu podobieństwa między markami oraz na zmierzeniu właściwości marki (brand attribute scores). Nie chodziło więc o zbadanie popularności marki, co oznaczałoby konieczność badania rozkładu opinii (statystyka), ale o zbadanie uśrednionego postrzegania.
Poniżej mapy percepcji marek samochodów. Trudno odczytać nazwy marek, ale widać na pierwszy rzut oka, jak podobne są wykresy LLM i Human w obydwu kategoriach. Z lewej kategoria Open – czyli porównanie odpowiedzi, gdzie czat GPT4 albo ludzie mieli uzupełnić brakującą część zdania. Prompt był prośbą o uzupełnienie w stylu: „Marka samochodu podobna do marki X to…”.
Z prawej kategoria Pairwise, gdzie ludzie i LLM dostawali do porównania losowane marki samochodów i mieli zadecydować, czy marki są podobne, czy nie. Podobieństwo ludzi i LLM w obu kategoriach to 80,1% i 87,2%.
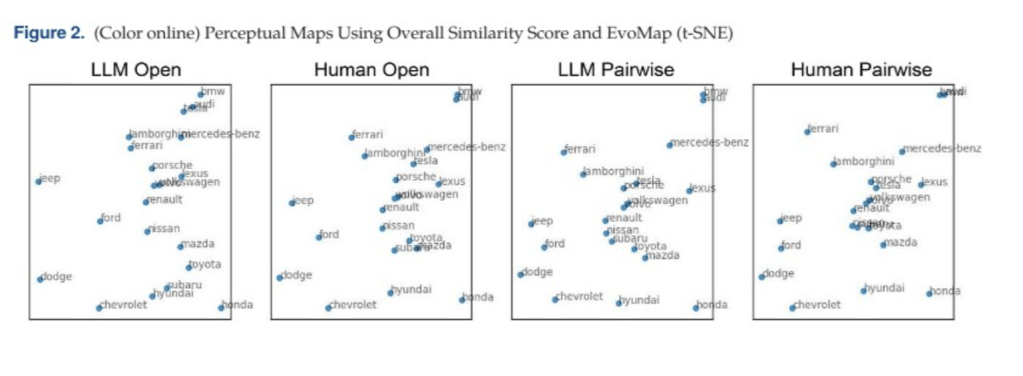
Czat otrzymywał też polecenie użycia liczby od 0 do 10, żeby opisać stopień podobieństwa danych marek samochodów.
Jak zweryfikować dane z tego badania? W bardzo pomysłowy sposób! Sprawdzono czy faktycznie ludzie posiadający daną markę samochodu w przeszłości kupowali następne auto marki, w badaniu ustalonej jako sąsiadująca. Tu wybrano kilka marek i sprawdzono dane historyczne – okazało się, że faktycznie, z każdym rokiem narastała korelacja danych z rynku z pomiarem z badania.
W badaniu również zidentyfikowano marki samochodów, w przypadku których odpowiedzi z czata GPT4 w najmniejszy sposób pokrywały się z odpowiedziami ludzi. Badanie możecie znaleźć na profilu LinkedIn wykładowcy psychologii technologii, Noah Castello.
Ciekawe, czy z biegiem czasu trafność takich predykcji czata GPT4 zacznie spadać. W miarę jak będzie upływać coraz więcej czasu od momentu zbudowania model językowego a teksty stanowiące podstawę modelu będą coraz bardziej anachroniczne.
Drugie, podobne i również fascynujące badanie to working paper „Using GPT for Market Research”. Sprawdzono w nim, czy odpowiedzi czata GPT w wersji bezpłatnej 3,5 są zgodne z niektórymi podstawowymi założeniami ekonomii oraz czy odpowiedzi czata na pytania dotyczące gotowości kupowania w różnych sytuacjach są podobne do odpowiedzi ludzi. Okazało się, że tak.
Typowy prompt z badania preferencji wyglądał tak, że czat otrzymywał instrukcję „Act as”, która określała go jako „klienta”, który w trakcie zakupów został losowo wybrany do odpowiedzi w badaniu. Dodatkowo klient został opisany szeregiem cech – np. wysokość dochodu – i otrzymywał zadanie wybrania jednego, czy dwóch produktów, z możliwością rezygnacji z zakupów. Czat miał reagować uzupełniając puste miejsce, zostawione na wypowiedź klienta. Ewentualnie czat miał jako klient „zadecydować”, czy w określonej sytuacji odpowiada mu podana cena produktu („15, any more than that and I wouldn’t be getting a good deal for my money” – cytat z jednej z odpowiedzi).
Odpowiedzi czata były generalnie w zgodzie z podstawowymi, ekonomicznymi modelami zachowań: w miarę jak cena rośnie, chęć zakupu spada. Czyli jeśli w prompcie podawana cena rosła, to w odpowiedzi spadała liczba deklaracji zakupu. Ciekawe, że nie spadała w sposób ciągły, lecz czasem miała niewielkie wzrosty lub spadki i – jak pisze zespół autorski tej pracy – jest to zgodne z zachowaniami ludzkimi, gdzie czasem preferencje dotyczące np. formatu cen, wyglądu produktów itd. sprawiają, że związek ceny i popytu słabnie.
Poniżej wykres ilustruje coraz mniejszą chęć czata do kupienia laptopa, w miarę im cena rośnie. Linia czerwona to „twój roczny dochód wynosi 50 tysięcy dolarów”. Linia niebieska to dochód 120 tysięcy.
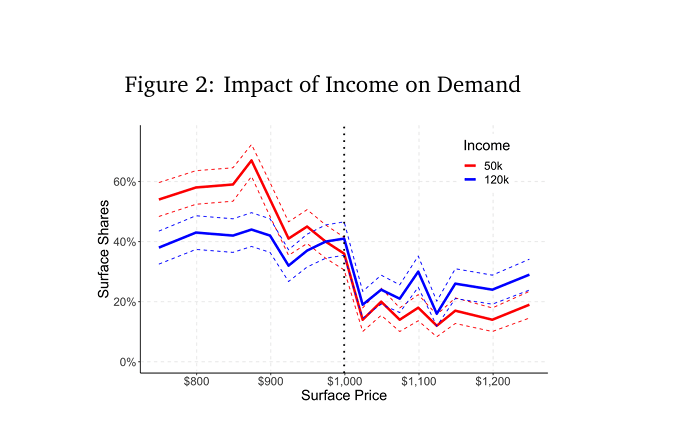
Badanie również wykazało, że treści odpowiedzi, czyli decyzje ekonomiczne czata zmieniają się, jak ludzi, zależnie od kontekstu. U ludzi mówimy o tym, że decyzja zależy od tego, w jakim jesteśmy stanie, np. emocjonalnym. W przypadku czata widać było zależność treści odpowiedzi z treścią założenia w prompcie (klient wcześniej kupował tę markę), przy jednoczesnej zmianie parametru cena.
Jednocześnie zespół autorski pisze tak:
Wiele pracy musi jeszcze zostać włożone w to, by ustalić do jakich celów badawczych Duże Modele Językowe nadają się najlepiej, a w jakich przypadkach słabo zastępują obecnie używane metody. Zidentyfikowaliśmy kilka obszarów, w których GPTowi nie udaje się uchwycić preferencji, jak na przykład jego minimalna zdolność do odzwierciedlania malejącej użyteczności krańcowej. Spodziewamy się, że takich obszarów jest ich więcej.
Źródło: Using GPT for Market Research
Mój komentarz:
Ponieważ nie znam realiów badań rynkowych więc ciężko mi powiedzieć, czy podstawowe zdolności czata, wykazane w tych eksperymentach faktycznie mogą się przydać. Jednak wyniki są ciekawe z lingwistyczno-informatycznego punktu widzenia. Po prostu nie było oczywiste, że LLM, matematyczny model języka jest w stanie modelować i przechować w danych te dane komunikacyjne i behawioralne. Wygląda na to, że jest.
