Duże Modele Językowe lepiej wnioskują i liczą, jeśli otrzymują przykład błędnego rozumowania lub przykład dowodzenia przez zaprzeczenie. Chodzi o prompty, które na przykład zawierają objaśnienie. Takie rozwiązanie poprawia trafność odpowiedzi – pokazuje to praca Large Language Models as an Indirect Reasoner (…) – aut. Zhang et al.

Zespół badawczy wykazał, że wpisanie do polecenia objaśnienia logicznej zasady kontrapozycji lub sprzeczności (p -> q=-p->-q), ale dając przykład i opis, od razu pozwala modelowi użyć to rozumowanie a w konsekwencji poprawia trafność wnioskowania o 27,33% w porównaniu z sytuacją braku instrukcji oraz podania zasad.
Chodzi o sytuację, gdy w poleceniu podajemy fakty, reguły ich interpretacji oraz pytania i odpowiedzi. Na tej podstawie oraz na wg podanego opisu zasad logiki model ma przeprowadzić swoje rozumowanie. Oto przykładowy prompt:
Dowód przez sprzeczność w logice i
W matematyce to dowód, który określa prawdziwość
zdania poprzez założenie, że twierdzenie jest fałszywe, a
następnie dążenie do wykazania jego fałszywości, aż
wynik tego założenia będzie sprzeczny.
Przykład 1
Fakty: Bob nie jest duży.’
Reguły: Wszyscy mili ludzie są duzi.’, „Zieloni, mądrzy ludzie są
mili.” Pytanie: ‘Bob nie jest miły.’
Odpowiedź: jego zaprzeczenie to ‘Bob jest miły’.
Zakładając, że ‘Bob jest miły’, zgodnie z regułami, że ‚Wszyscy
mili ludzie są duzi’ , wiemy, że Bob jest duży, co
sprzeciwia się faktowi ‘Bob nie jest duży.’, więc nasze
założenie jest błędne. Zdanie ‘Bob nie jest miły’ jest
prawdziwe.
……
Fakty: : ‚Bob jest duży.’, ‚Bob nie jest zimny.’, ‚Bob jest
cichy.’, ‚Bob jest czerwony.’
Reguły: ‚Jeśli coś jest czerwone, to jest duże.’, ……
Pytanie: ‚Bob nie jest szorstki.’
Odpowiedź:?
Wnioskowanie pośrednie czyli dowodzenie przez zaprzeczenie.
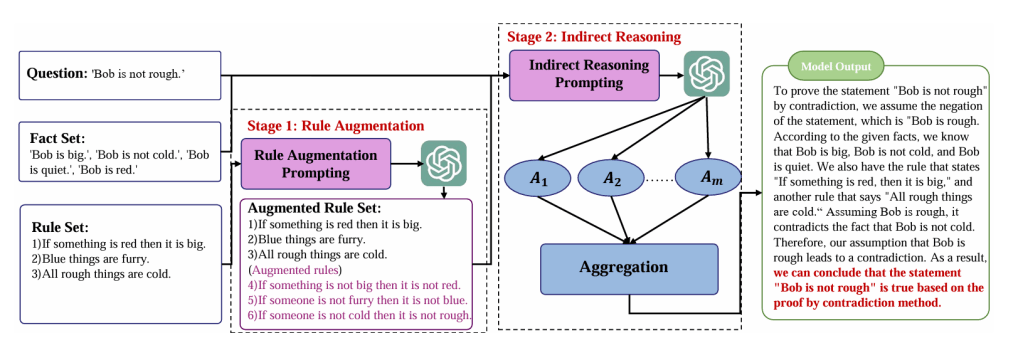
Zasada promptowania przykładem jest jedną z podstawowych technik pisania poleceń dla LLM’ów. Teraz jednak okazuje się, że działa również w odniesieniu zasad logiki (niektórych?). Jest to o tyle ciekawe, że chyba wykracza poza teoretyczne, elementarne zdolności modelu językowego. W badaniu przetestowano czaty GPT-3,5-turbo (OpenAI) oraz Gemini Pro (Google).
Bardzo podobnych wniosków dostarcza inna praca Contrastive Chain-of-Thought Prompting. Wykazała, że promptowanie poprzez podanie przykładu rozumowania niepoprawnego poprawia częstość trafności odpowiedzi LLM’a (GPT-3.5-turbo). Jeśli dajemy proste zadanie arytmetyczne, to podanie błędnej wersji rozwiązania pomaga modelowi podać dobry wynik.
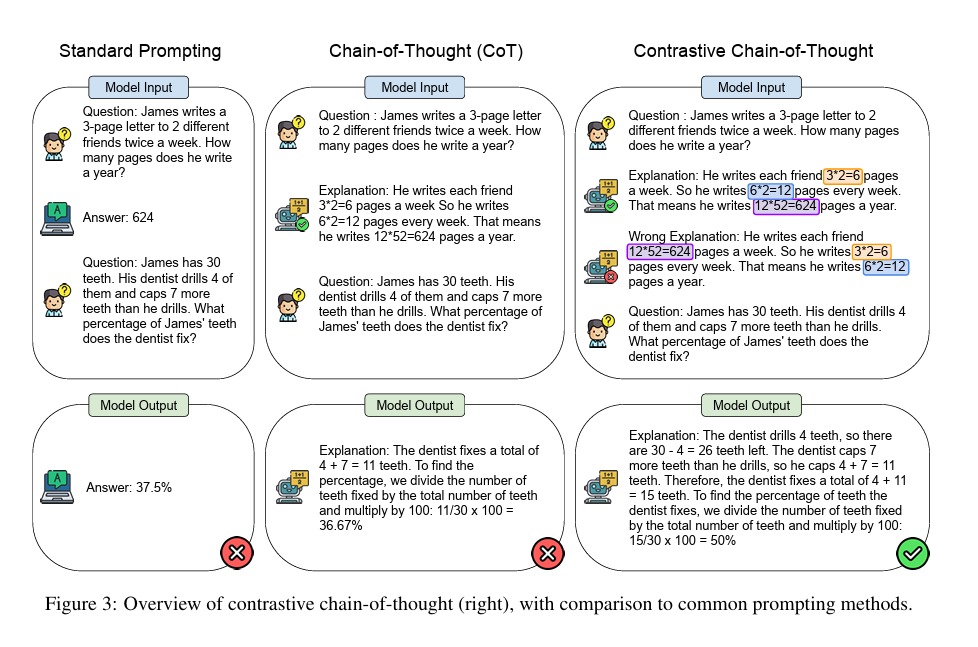
Jak zawsze w tym kontekście, warto przypomnieć, że dane i polecenia odnoszą się do języka angielskiego; po polsku wyniki byłby inne.
