Wiecie dlaczego eksperci/ekspertki od AI są autentycznie przejęci możliwościami technologii a pozostali ludzie niespecjalnie? Bo jak eksperci patrzą na wykresy możliwości sztucznej inteligencji, to widzą, że wystartowała rakieta i leci w naszym kierunku. Wcale nie wiadomo jednak, kiedy doleci.
Problem też polega na tym, że ta „rakieta” leci za wolno, żeby ją było widać gołym okiem, a jednocześnie za szybko, żeby można było przygotować na nią firmy, branże i gospodarki. Miliony lat ewolucji nie przygotowały nas na rozumienie trendów, bo w przyrodzie albo organizmy wyrażają trendy, albo muszą sobie z nimi radzić, ale ich nie analizują.
To najsłynniejszy z tych wykresów.
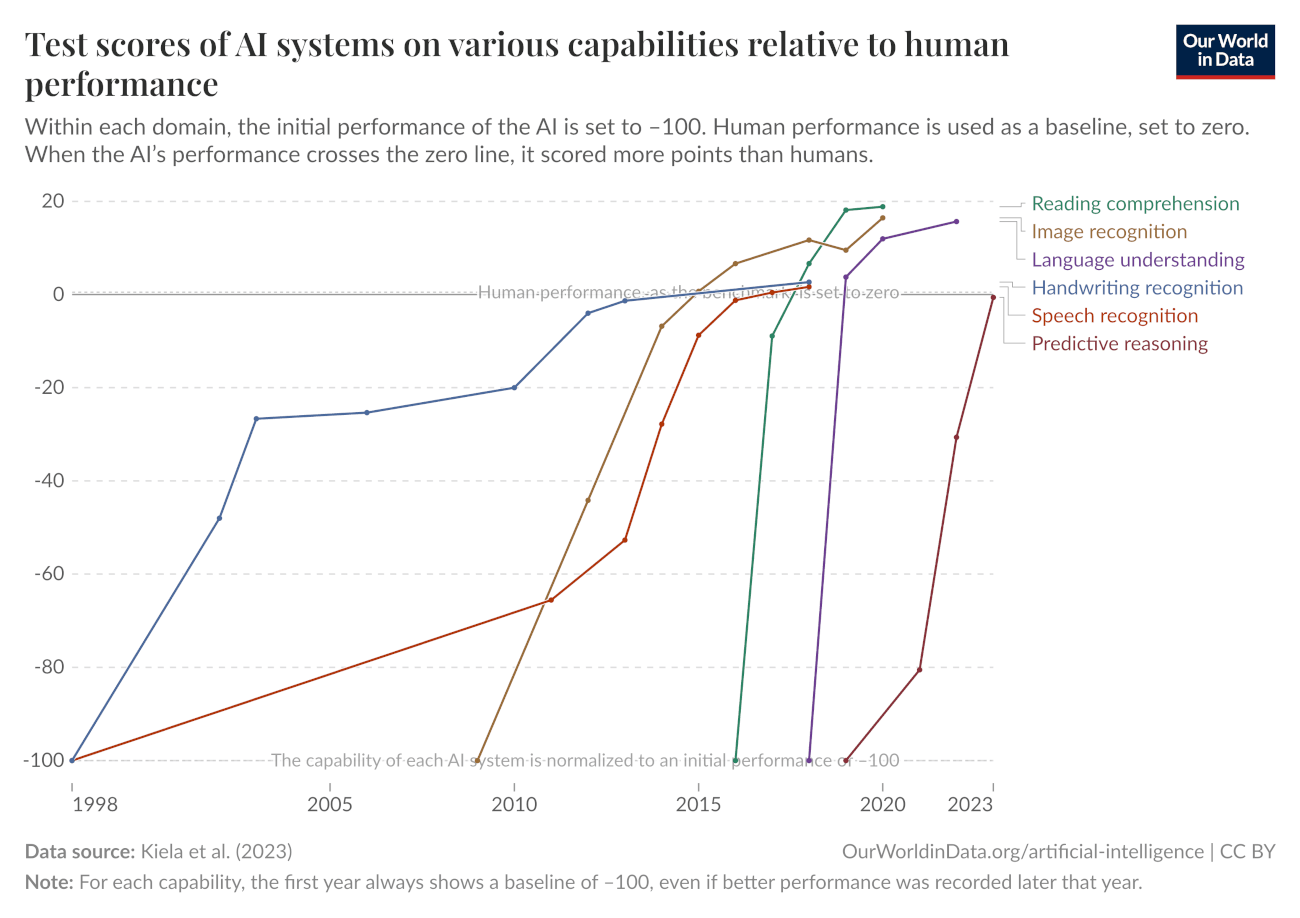
W głowie się kręci od takich wzrostów, co? Od zera do bohatera. Ale trzeba pamiętać, że postęp systemów AI przeważnie dotyczy wąsko zdefiniowanych zadań testowych
w warunkach laboratoryjnych.
Wykres pokazuje serię skoków. Linie nie rosną równomiernie. Taki obraz sugeruje, że za poprawą wyników stoją duże zmiany: zmiana technologii, ale również zmiana testów. W efekcie wykres opowiada historię technologicznych przełomów i przesuwających się definicji sukcesu. To nie jest sytuacja stabilnie mierzonej technologii.
Opowiem Wam dzisiaj o paru takich „rakietowych” wykresach i nieporozumieniach z nimi związanych. Część tych wykresów lekko wykpimy, trochę będziemy dzielić włos na czworo (w końcu to obowiązek każdego piszącego mądrali), ale zaczniemy od trzęsienia ziemi.
Rakieta 50%
Ten wykres pochodzi z organizacji METR (Model Evaluation & Threat Research). Nazwę mają trochę jak paramilitarna organizacja z filmu science-fiction, której celem jest ocalenie
albo zniszczenie ludzkości.

Tymczasem oni sprawdzają, czy jak długie i jak skomplikowane są zadania komputerowe, które AI umie wykonać w połowie przypadków. Czyli daję, ona robi i mamy 50% szans, że jej to wyjdzie. Głównie chodzi o zadania programistyczne, komputerowe, liczbowe.
METR twiedzi, że „Duże Modele Językowe” – gadająca z nami sztuczna inteligencja ulepsza się wykładniczo. Co 7 miesięcy modele potrafią dwa razy więcej niż poprzednie.
W 2019 roku AI umiała wykonywać zadania, które człowiekowi zajmują parę sekund. Technologia, która zaoszczędzi ci trzy sekundy dziennie? Na co je przeznaczysz? Pewnie nie możesz się zdecydować.
Pod koniec roku 2025 sytuacja wygląda zupełnie inaczej. Claude Opus 4.5 potrafi już wykonywać grubo z ponad 50% pewnością zadania, które ludziom zabierają ponad 4h. Czasem jak się zabierze za tę pracę, to ją wykona 3x niż człowiek a czasem wykona ją 5x wolniej niż człowiek.
W metrykach 50-procentowy wskaźnik sukcesu w złożonym, wieloetapowym zadaniu jest triumfem inżynierii. Ale jak się zastanowić, to ja straciłbym każdą pracę mając 50%
skuteczność.
Czy „w połowie kompetentny” bóg jest w ogóle użyteczny? Mamy do czynienia z technologią największej zmiany? Czy to raczej nadciągające tsunami bałaganu do posprzątania przez ostatnich szczęśliwców na etacie?
Klif ujemnej wartości dodanej
Załóżmy, że jest gdzieś jakiś bezwzględny menedżer, który coś przeczytał, coś usłyszał i chce szybko zamiast drogich i wolnych ludzi mieć szybkich i tanich agentów. Czy to już?
Koszt pracownika to nie tylko jego pensja; to także „koszt monitorowania”. Rzetelny pracownik, powiedzmy, 95%+ sukcesu w rutynowych zadaniach, pozwala kierownictwu na drzemkę, spokojny lanczyk w centrum, autopromocję w soszjalach. Koszt monitorowania jest bliski zeru.
Pracownik ze wskaźnikiem sukcesu 50% generuje koszt monitorowania, który często przekracza wartość samej pracy. Jeśli menedżer musi poświęcić 40 minut na weryfikację pracy, którą Claude wykonał w 5 minut, a następnie potencjalnie kolejne 40 minut na jej poprawianie, czas nie został zaoszczędzony. Praca została jedynie przesunięta z kategorii „wykonywanie” do kategorii „audytowanie”. W ekonomii nazywa się to ujemną wartością dodaną przy uwzględnieniu kosztów transakcyjnych.
Wyniki METR pokazują silną korelację między długością zadania a ryzykiem porażki:
Tabela 1: Sukces AI w zależności od czasu trwania zadania (dane szacunkowe na podst. METR)
| Czas trwania zadania (Ludzki) | Wskaźnik Sukcesu AI | Interpretacja Menedżerska |
| < 4 minuty | ~100% | Bóg Małych Chwil. Idealny asystent. |
| ~ 50 minut | ~50% | „Rzut Monetą”. Niebezpieczny stażysta. |
| > 4 godziny | < 10% | Katastrofa. Bezużyteczny szum. |
| 2 |
Tylko na wykresie to jest łagodne przejście. To w realu jest zapaść – spadek z klifu. „Horyzont 50%” w wielu zastosowaniach, w wielu branżach jest momentem, gdy model przechodzi ze kategorii „użyteczne narzędzia” do kategorii pułapka.
Czemu? Wbrew intuicji to narzuca rachunek prawdopodobieństwa. Im więcej etapów działania mającego 50% szans na sukces, tym bardziej prawdopodobieństwo błędu zbliża się do 1, czyli sytuacji, gdy błąd jest pewny.
Nawet jeśli agent jest w 99% dokładny na każdym kroku a sukces z jednego kroku nie zmienia szans na sukces w kolejnym a zadanie wymaga 100 kroków, to całkowity wskaźnik prawdopodobieństwa sukcesu wynosi:
0.99^100 ≈ 36.6%Zanim zaczniesz wdrażać agenty i chatboty zastanów się, czy jak bardzo możesz zabezpieczyć się przed tym, co musi kiedyś się wydarzyć. System wyprodukuje czasem nawet piramidalne bzdury, pięknie je zapakuje i wyśle do odbiorców z życzeniami.
Dwa praktyczne pytania:
1. Czy w twojej branży pomyłka jest dopuszczalna i w jakich działaniach? Wybierz te, gdzie będzie zysk dla personelu, ale koszt pomyłki mały.
2. Czy weryfikacja działań AI będzie prosta i tania? Wybierz te, gdzie wykrycie błędu będzie szybkie lub proste. Zadanie nie może być mądrzejsze niż ludzie, którzy je oceniają.
Słyszałem kiedyś wystąpienie prawnika specjalizującego się w RODO. Mówił, że często używa w swojej pracy modelu Gemini od Google i że ten model potrafi generować idealnie poprawne oceny prawne z zakresu RODO, włącznie ze wskazywaniem norm oraz aktów wykonawczych.
Jako ekspert – dodał: – Nie mam w takich przypadkach nic do poprawy. Problem jednak z przypadkami, gdy Gemini się myli. Ja to idzę to na pierwszy rzut oka, że model wymienia nieistniejący akt prawny. Ale jeśli ktoś nie ma tej wiedzy, to na sprawdzenie dużego pisma poświęcić będzie musiał dużo czasu.
Wskaźnik bałaganu
Zadania oceniane przez METR najpierw zostały określone i zmierzone. Do tego trzeba było nagrać i ocenić ponad 2529 godzin pracy ekspertów, aby ustalić normy.
Zadania podzielono na trzy koszyki:
- SWAA (Software Atomic Actions): Zadania zajmujące ludziom 1–30 sekund (np. „zmień wielkość czcionki w CSS”).
- HCAST: 97 różnorodnych zadań programistycznych zajmujących od 1 minuty do 30 godzin.
- RE-Bench: Waga ciężka – zadania inżynieryjne z zakresu badań nad uczeniem maszynowym, zajmujące około 8 godzin.
Uwzględniono nawet „wskaźnik bałaganu” (messiness score), przyznając, że niektóre zadania są trudne nie dlatego, że są intelektualnie głębokie, ale dlatego, że są słabo zdefiniowane – odpowiednik zadań typu „popraw to jakoś, bo mi się nie podoba’”.
W jednej z firm, gdzie doradzaliśmy używanie chatbotów miałem podobną rozmowę. Pytam ich, czy mają jasno opisany swój styl pisania treści. Mówią, że nie. Pytam ich, to skąd wiecie, jak pisać w waszym stylu i czym się różni wasz styl od stylu konkurencji. Oni patrzą chwilę zdziwieni i po paru sekundach ktoś mówi zdziwiony odrobinkę, że piszą jak zawsze pisali.
Gdyby mieli swój styl, swoje polityki, swoje zasady to od razu wiedzieliby, jak należy stworzyć zasady pracy chatbotów i zasady pracy systemów agentowych. Systemy agentowe to upraszczając chatboty, które mają pamięć, autonomię oraz używają innych programów komputerowych – możesz im kazać, żeby np. na podstawie informacji z terenu, na przykład pisały wiadomości, posty, tworzyły scenariusze – żeby coś zlecały innym chatbotom.
Całe branże, działy w firmach a być może narodowe gospodarki ratuje lub maskuje wspomniany „wskaźnik bałaganu”. Sztuczna inteligencja mogłaby zostać wdrożona i użyta, ale ponieważ w tych firmach czy w tych krajach nie lubi się procedur, opisów, standardów itd. więc marsz technologii będzie tam wolny. Aż do pewnego momentu, gdy nie da się już po staremu.
Ale będzie to moment niewesoły.
Kolorowe klocki jako reduta ludzkiego umysłu
Benchmark ARC-AGI (Abstraction and Reasoning Corpus) to dla wielu święty Graal testów sztucznej inteligencji. Idea była taka, żeby tworzyć zestawy zadań logicznych, obrazkowych, które będą łatwe dla człowieka, ale trudne dla maszyny. Upraszczając: chodzi o rozpoznawanie zasad, wg których układane są sekwencje kolorowych klocków. Jeszcze dwa lata temu tylko 2-3% tych zadań było w zasięgu modeli.
A teraz? Połowa drogi już za nimi! Ostatnie wyniki:
- GPT-5.2: 52.9%. To jest gigantyczny skok. Przekroczenie progu 50% w ARC-AGI-2 to moment, w którym zaczynamy się zastanawiać, czy model nie zaczyna „rozumieć” w sposób zbliżony do ludzkiego.
- Claude 4.5 Opus: 37.6%.
- Gemini 3 Pro: 31.1%.
Oprócz skoku skuteczności równie ciekawy jest spadek kosztów obliczeń potrzebnych do rozwiązania tych zadań. Modele wyraźnie lepiej rozwiązują zadania, ale koszt obliczeń rośnie bardzo powoli – prawie nie rośnie.
Ten test stał się tak prestiżowy, że choć autorzy tego pomiaru specjalnie nie ujawniają zbyt wiele, to wielkie firmy mające wielomiliardowe budżety po prostu zainwestowały w rozszyfrowanie tych zasad i nagle modele zaczęły w tym konkretnym teście zbliżać się do granicy – za tą granicą podobno tylko ludzki intelekt.
To oczywiście przesada i nieprawda, bo nie umiemy wytyczyć ani granic ludzkiej inteligencji, ani ludzkiej świadomości. Jak złośliwie zauważył uważny obserwator problemu, filozof i analityk AI dr Iwo Zmyślony, w momencie, gdy modele osiągną tą umowną granicę, zostanie ona po prostu przesunięta. Sami autorzy testu natomiast twierdzą, że starali się uczynić test niemożliwym do wytrenowania, ale prawdopodobnie firmy tworzące AI rozgryzły, jak przygotować swoje modele do testu.
Test ARC-AGI w kolejnych odsłonach miał sprawdzać, jak modele AI radzą sobie, gdy nie można wykuć na blachę zasad działania, gdy reguł jest wiele, a co gorsza te reguły wzajemnie jakoś na siebie wpływają. Im większe nasilenie tej płynności zadania, tym gorzej wypadała maszynowa inteligencja.
Cynicznie można powiedzieć, że jeśli organizacja tworząca testy ma mniejszy budżet niż organizacja rozwiązująca testy, to sprawa jest przesądzona.
Pamiętajmy jednak o drugiej, ludzkiej stronie medalu. Te zadania wcale nie są wszystkie łatwe dla wszystkich ludzi. Miały być łatwe dla wszystkich, ale nie są. Demografia badań na ludziach nie jest ujawniana. Organizatorzy po prostu mówią, że np. ARC-AGI 2 sprawdzono na 400 osobach i że prawie (9 na 10) wszyscy umieli rozwiązać dane im pary zadań.
Spory problem tego rodzaju badań polega na tym, że inteligencja ludzi nie jest jasno zdefiniowana a ludzkie możliwości bardzo się różnią w ramach naszego gatunku. Niezbyt przesadzając a może w ogóle nie przesadzając: istnieją już chatboty mądrzejsze od najgłupszych ludzi, którzy mają pracę, mają karierę i zarabiają. Jedyna przewaga takich ludzi jeszcze to zdolność działania w fizycznym świecie.
Krótka dygresja: podobno w amerykańskim parku narodowym Yellowstone był problem z niedźwiedziami buszującymi w koszach na śmieci. Zapytano leśnika (ranger) kierującego tym odcinkiem, czemu kosze nie zostaną wyposażone w blokady niemożliwe do pokonania przez niedźwiedzie. Leśnik zasugerował, że niestety, ale inteligencja najgłupszych ludzi i najmądrzejszych niedźwiedzi nakładają się wzajemnie – czyli blokady koszy na śmieci, które będą za trudne dla wszystkich niedźwiedzi, będą też za trudne dla niektórych ludzi. Natomiast blokady koszy łatwe nawet dla najgłupszych ludzi, będą też w zasięgu najmądrzejszych niedźwiedzi.
W tej metaforze my jesteśmy ludźmi a sztuczna inteligencja jest niedźwiedziem. Raczej nie jest papugą.
Papuga wygrywa olimpiadę matematyczną
O modelach językowych mówi się czasem, że są jak papugi, które powtarzają słowa, ale bez zrozumienia. Decyduje to, jakiej definicji rozumienia używamy. Poniżej w tabeli macie wynik, który mówi, że „gadające papugi” są lepsze od młodzieży licealnej i z pierwszych lat studiów, gdy chodzi o zadania z olimpiady matematycznej. Co on oznacza? Ktoś zaraz straci pracę?
Ten wynik jest oznaką siły zespołów trenujących modele dla wielkich firm. Gdy takie zespoły zobaczą domenę, w której jest łatwo uczyć model – są dane – i jest zachęta finansowa, to potrafią dowieźć wynik.
| Model | Wynik AIME 2025 (No Tools) | Wynik AIME 2025 (With Code) | Komentarz |
| GPT-5.2 | 100.0% | 100.0% | Fizyk, prof. Andrzej Dragan mówi, że te zadania są oryginalne, wymagające i nietrywialne. |
| Gemini 3 Pro | 95.0% | 100.0% | Jeśli sobie wygeneruje kod, to dogania GPT, ale bez tego minimalnie ustępuje. |
| Claude 4.5 Opus | 92.8% | (brak danych) | Nadal wybitny wynik, ale w tej lidze 7% różnicy to przepaść. |
| Gemini 3 Flash | 90.4% | – | Największe zaskoczenie. Model budżetowy osiąga wynik, o którym GPT-4 mógł tylko marzyć. W ogóle zachęcam do testowania modeli tańszych! |
| Grok 4.1 | 94.0% | – | Warty odnotowania gracz z boku – tym bardziej, że jest bardzo szybki. |
Źródło danych: OpenAI, Google Deepmind
Wniosek: Mój znajomy profesor matematyki (kryptograf – matematyk) parę tygodni temu wyraźnie zaskoczony publikował na swoim profilu na Facebooku, że dał chatbotowi do przeprowadzenia dowód matematyczny. Wynik? Poprawny! To jest coś nowego i w 2026 będzie jeszcze więcej takich przypadków. Profesor fizyki Dragan mówi, że te możliwości sieci neuronowych pokazują, że w niektórych przypadkach umieją one uogólniać i przenosić obserwacje, naukę z jednego problemu na inny.
Niebawem te cechy modeli przełożyć się mogą na zdolność prowadzenia analiz finansowych, analiz ryzyka itd. Pytanie, z jaką skutecznością. Nie wiemy! No i jaki byłby efekt wprowadzenia modeli do tych branż?
Pesymista powie, że firmy automatycznie tworzące analizy będą nieprzejrzyste, będą gorzej traktować przypadki nietypowe. Optymista będzie liczyć na to, że usługi stanieją, skoro można tworzyć modele ryzyka seryjnie i naciśnięciem palca.
Dystrybucja ryzyka
Metoda z METR jest próbą wyjścia z impasu. Historycznie, benchmarki AI są i były abstrakcyjne i to tworzy problem. Modele testowane są na „MMLU” (Massive Multitask Language Understanding) czy „GSM8K” (matematyka na poziomie szkoły podstawowej). Te wyniki mówią nam, że AI potrafi odpowiedzieć na pytanie wielokrotnego wyboru z biologii albo rozwiązać zadanie z treścią o jabłkach i pomarańczach. Nie mówiły nam jednak, czy AI potrafi wykonać pracę. Nie mówiły, jak sprawdzi się w realnym świecie.
Z jednej strony wskaźnik METR odnosi się do realnie występujących zadań, opisanych przez ludzi, którzy się na nich znają. Definicja jest zwodniczo prosta: mierzymy, jak długie i jak skomplikowane może być zadanie, które AI wykona z 50% pewnością. Czyli mierzymy wiele razy oraz jednocześnie porównujemy z czasem, jakiego potrzebowaliby ludzie na wykonanie tego samego zadania.
Diabeł jednak, jak zawsze, tkwi w mianowniku. Jeśli metryka skalibrowana jest wokół 50%, to trochę tak, jakby oceniać niezawodność samochodu, mówiąc, że jest on zdolny do przejechania 100 kilometrów – ale pod warunkiem, że w połowie przypadków stanie wcześniej i tylko módlmy się, żeby awaria była bliżej 90 kilometra.
Teraz ważna rzecz: my nie wiemy, gdzie i jak psuje się ten samochód. Dystrybucja ryzyka w przypadku zastosowań sztucznej inteligencji generatywnej nie jest dobrze rozpoznana. To ciekawy, warty odnotowania paradoks technologii. Ludzie, którzy ją tworzą, sami nie umieją ocenić, co ona w chaotycznym, ludzkim świecie będzie umiała wykonać.
Maszyny od bardzo niedawna umieją mówić, pisać, tworzyć wideo, obrazy – nauczyły się szybko w krótkim czasie i wcale nie przestały się zmieniać. To jeden z powodów, dla których nie ma instrukcji obsługi tej technologii. Każdy więc musi testować technologię na swoich problemach, swoich zadaniach. Każdy w sumie pisze instrukcję obsługi dla siebie. Od nowa. To będzie potężny hamulec dla wdrożeń.
Place your bets
Marzenie o Sztucznej Inteligencji polega na tym, że dajesz jej cel („Zbuduj mi aplikację”) i to uruchamia pętlę: Planuj -> Wykonaj -> Sprawdź -> Napraw -> Powtórz.
Jeśli pojedynczy prompt do LLM jest rzutem monetą, to „Pętla agentyczna” (Agentic Loop) jest ruletką. Kto w tym porównaniu jest kasynem, które przecież zawsze wygrywa. Kto jest tym kasynem? Dostawca chmury obliczeniowej, wystawiający fakturę za tokeny.
W debacie, którą moderowałem w tym roku na Konferencji Masters & Robots w tym roku, specjalista od AI z firmy InPost bardzo podobnie i złośliwie podsumował, że jego zdaniem termin „sztuczna inteligencja” to przede wszystkim sposób na droższe sprzedawanie mocy obliczeniowej.
Rzeczywistość czasem jednak wygląda tak.
- Krok 1: Agent pisze kod albo coś generuje (Sukces: 50%) -> Porażka.
- Krok 2: Agent czyta komunikat o błędzie. „Aha, widzę. Naprawię to.”
- Krok 3: Agent generuje na nowo coś, żeby naprawić Błąd A, ale wprowadza Błąd B.
- Krok 4: Agent czyta Błąd B. „Przepraszam. Naprawię to.”
- Krok 5: Agent przywraca kod, który spowodował Błąd A.
Zawsze będę pamiętał ten moment, gdy po 8h siedzenia z Gemini od Google odkryłem, że naprawiamy błąd, którego wcześniej nie było, czyli sami go umieściliśmy w kodzie. Zdarzyło mi się też przepalić milion tokenów, czyli ok 30 dolarów kredytu obliczeniowego na samym przesyłaniu dokumentów – nie zauważyłem, że agent miał dostęp do obszernych dokumentów, które radośnie zaczął czytać, choć nikt mu nie kazał.
Stałe grzeszki agentów to właśnie skupienie na działaniach niepotrzebnych, zapominanie lub nieuwzględnianie podanej informacji, rozdymanie kosztów pracy. Tak czy owak, kasyno wygrywa.
Czy można ograniczyć straty? Tak.
- Podstawą jest przemyślany i klarowny projekt zadania czy procesu.
- Plan podzielony na etapy, które zamykane są testem.
- Po wydaniu iluś tam pieniędzy na błędy uczymy się, jak dopasować wymagania do możliwości maszyny.
Kiedy 50% to 100%?
W świecie zadań generatywnych (burza mózgów, poprawa tekstu, tworzenie e-maili, tworzenie obrazków), 50% to wynik rewelacyjny.
Jeśli poproszę o 10 pomysłów na logo i 5 jest dobrych, jestem zachwycony. Koszt porażki jest zerowy (po prostu ignoruję te złe i widać je od razu). Dlatego w branżach kreatywnych, jeśli koszt generowania nie jest duży, te narzędzie już dziś są absolutnym przełomem. Tak samo we wszystkich branżach komunikacyjnych (marketing, PR, różne rodzaje działalności medialnej). 50% skuteczności? Nic nie szkodzi! Wygeneruję wiele razy i mam pewność, że coś mi się przyda.
W świecie zadań wykonawczych (kodowanie, decyzje finansowe, prowadzenie pojazdów, chirurgia), 50% to katastrofa. Koszt porażki jest niezerowy; często jest ujemny (koszty sprzątania, odpowiedzialność prawna, przestoje).
Wykres METR mierzy „zdolność” (czy model teoretycznie potrafi wykonać zadanie), a nie „niezawodność” (czy potrafi to zrobić bez mojego nadzoru). Dla menedżera wykonawczego liczy się tylko to drugie.
Tu jednak kłania się drugi rodzaj używania AI: Augmentacja vs Automatyzacja. Jeśli użycie AI w zespołach nie zastępuje ludzi, ale przyspiesza ich pracę? Jeśli poprawia ich efektywność? Jest tylko ten kłopot, że akurat w kreatywnych branżach i w zadaniach generatywnych do tej pory firmy i ludzie nie wprowadzali jasnych metryk i opisów tego, co uznajemy za udane. No, uznajemy to, co do tej pory uznawaliśmy. Takie podejście znacznie utrudnia metodyczne wprowadzenie technologii.
Bez rusztowania nie da rady
A gdyby tak wziąć ludzi, którzy mają doświadczenie w jakiejś branży i dać im zadanie wykonywane przy użyciu komputera oraz to samo zadanie dać modelom językowym? Czy takie porównanie coś nam powie o rozwoju technologii i jej możliwościach? Ile razy w pojedynku wygrywa dziś człowiek?
W nieco ponad połowie przypadków. To zależy od branży, ale średnio to 53% przypadków. Dla mnie to byłoby bardzo mało.
Test wyglądał tak, że osoby doświadczone (tzw. eksperci/ekspertki) robiły zadanie, które jest typowe w danym zawodzie. To samo zadanie dostawał np. chat GPT albo Claude a potem oba wyniki szły niepodpisane do kolejnego człowieka, który nie wiedział kogo ocenia – miał wskazać lepiej zrobioną pracę.
Tak czy owak, najciekawsze w tym badaniu nawet nie jest to, że modele zaledwie w ciągu roku 3x poprawiły swoją skuteczność w tego typu testach. Ciekawsze jest, że największe oszczędności czasu oraz pieniędzy osiągano, gdy człowiek nadzorował pracę sztucznej inteligencji. Człowiek sprawdzał, projektował tę pracę, wymyślał procedury. To się nazywa po angielsku „augmenting” – wzmacnianie a praca wg reguł, etapami to „scaffolding”. Tworzymy naszymi regułami oraz wiedzą rusztowanie, które musi wspierać sztuczną inteligencję.
Zyski z takiego podziału pracy na człowiek razem z AI to np. ponad dwa razy taniej i trzy razy szybciej.
Niestety, wiarygodność tego badania obniża fakt, że całe badanie zostało wymyślone i zorganizowane przez firmę OpenAI, czyli producenta chata GPT. Z jednej strony stać ich było na to, żeby w badaniu pokazać jak ich model przegrywa z konkurencyjnym modelem Claude.
Z drugiej strony, nie byli transparentni i nie uzasadnili, dlaczego i jakie zawody oraz zadania wybrali z jakiej puli do tego badania. Po prostu napisali 44 zawody z 9 topowych sektorów gospodarki. Czy wybrali obiektywnie? Czy wybierali zawody, zadania łatwiejsze dla algorytmów? Stawka takich badań jest duża z wizerunkowego punktu widzenia. OpenAI w 2025 przekroczyło roczny przychód wysokości 20 miliardów dolarów.
Orka z podkulonym ogonem
Trend „podwajania co 7 miesięcy” w pewnym momencie uderzy we „Front Pareto” – czyli granicę, na której kończą się najszybsze i najtańsze do osiągnięcia poprawy jakości. Pierwsze efekty dają nieproporcjonalnie duże korzyści, ale każda kolejna poprawa wymaga coraz więcej pracy.
Jeśli tak się jeszcze nie stało, to dlatego, że nie wyszliśmy jeszcze z fazy hucznie ogłaszanych sukcesów teoretycznych w tym albo tamtym egzaminie i benchmarku. Dopiero kolejna faza wdrożeń, eksperymentów w świecie realnym pokaże, ile warte były te wszystkie 80-90 procentowe sukcesy w tabelach.
Przejście od 0% do 50% (automatyzacji lub skuteczności w typowych przypadkach) jest trudne, ale możliwe dzięki dodawaniu danych i mocy obliczeniowej. Potem przejście od 50% do 80% (obsługa mniej typowych, bardziej zróżnicowanych sytuacji) jest już znacznie trudniejsze.
Przejście od 90% do 99,999%, czyli poziomu niezawodności znanego jako „Six Sigma” (standard zarządzania jakością zakładający mniej niż kilka błędów na milion operacji) może zająć dekady.
Ekscytacja lat 2024–2025 to ekscytacja początkowym wzrostem i szybką poprawą – najpierw w testach a potem w zastosowaniach, których nie ma wiele. Za chwilę wejdziemy w fazę orki, czyli żmudnej, mało widowiskowej pracy inżynieryjnej. Wtedy da o sobie znać „długi ogon” przypadków brzegowych.
To będą rzadkie, nietypowe sytuacje, które razem składają się na dużą część realnej pracy – dziwny stary kod, niejednoznaczne e-maile od klientów, niepisane zasady biurowe – to miejsce, gdzie leży pozostałe 50% problemów. AI będzie mieć z tym problem, bo z definicji trenuje na medianie i uczy się tego, co przeciętne i powtarzalne, a nie tego, co rzadkie, lokalne i zależne od kontekstu.
Dolina niesamowitości kompetencji
Dolina niesamowitości to termin opisujący niepokojące podobieństwo, które jest jednocześnie rozpoznawalne i fałszywe zarazem. Żyjemy dziś w dolinie niesamowitości kompetencji. Coś rozpoznajemy, ale nie do końca. Obraz jest znajomy, a zarazem obcy. Maszyny są zbyt dobre, by je ignorować, lecz zbyt ułomne, by im ufać.
Wykres METR jest prawdziwy. Postęp jest oszałamiający. Zdolność Claude 3.7 do wykonania 50-minutowego zadania z 50-procentowym sukcesem to cud techniki, który w 2020 roku wydawałby się magią.
W rachunku rynku ekonomicznym 50% to jednak liczba niebezpieczna. To „strefa śmierci”, gdzie narzędzie wygląda na wystarczająco zdolne, by zastąpić człowieka, ale jest wystarczająco nierzetelne, by zniszczyć biznes, jeśli pozostawi się je bez nadzoru.
Do menedżerów czytających ten raport: Strzeżcie się wykresu „wykładniczego”. Mierzy on surową moc – nie zaś przemysłową użyteczność. Zwalnianie dziś ludzi, by zatrudnić agentów to jak sprzedaż samochodu, by kupić teleportację, która zadziała w 50% przypadków. Kiedy zadziała, to mamy natychmiastową podróż i po sekundzie jesteś, dajmy na to w Tajlandii na plaży. Ale w połowie przypadków kończysz zintegrowany ze ścianą.
Do pracowników umysłowych: Wasza praca jest bezpieczna, na razie – być może będzie jej mniej, ale tego nie wiadomo. Opis waszego stanowiska jednak w praktyce się zmienia. Nie jesteście już „autorami” ani „koderami”. Stajecie się de facto „weryfikatorami”. Jesteście tłumikami w pętli sprzężenia zwrotnego, audytorami mechanicznych niedźwiedzi,
stochastycznych papug.
Raport sporządzony przez Starszego Analityka ds. Sceptycyzmu Technologicznego.
22 stycznia 2025.
Czytelnia:
https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/
https://arxiv.org/pdf/2510.04374
nytimes: podcasts/hardfork-ai-science
